Facing uncertainty about AI, the instinct is to slow down — pause it until policy catches up. The evidence from the last two years says that instinct, applied as a blanket restriction, produces the opposite of safety. It yields slower delivery and more unmanaged risk. The better move is to test under controls, measure, and write the policy from what the test shows.
It's a policy choice, not a technology question
The question is rarely whether AI is safe in the abstract. It is how an organization learns what AI is worth in its own process: by testing it under controls, or by ruling on it before the evidence exists. A full stop feels safe. It usually is not — it removes a force multiplier and hides the use it cannot stop.
Governance and speed move together
None of this is opinion; it is the consistent finding of independent enterprise surveys and peer-reviewed field experiments across 2023–2026. AI use is already the norm — 78% of organizations reported using it in 2024 — yet only about a third have a formal AI policy. Organizations that build stronger governance adopt AI faster, not slower. And restriction does not stop AI use; it pushes it into unmanaged "shadow" channels.
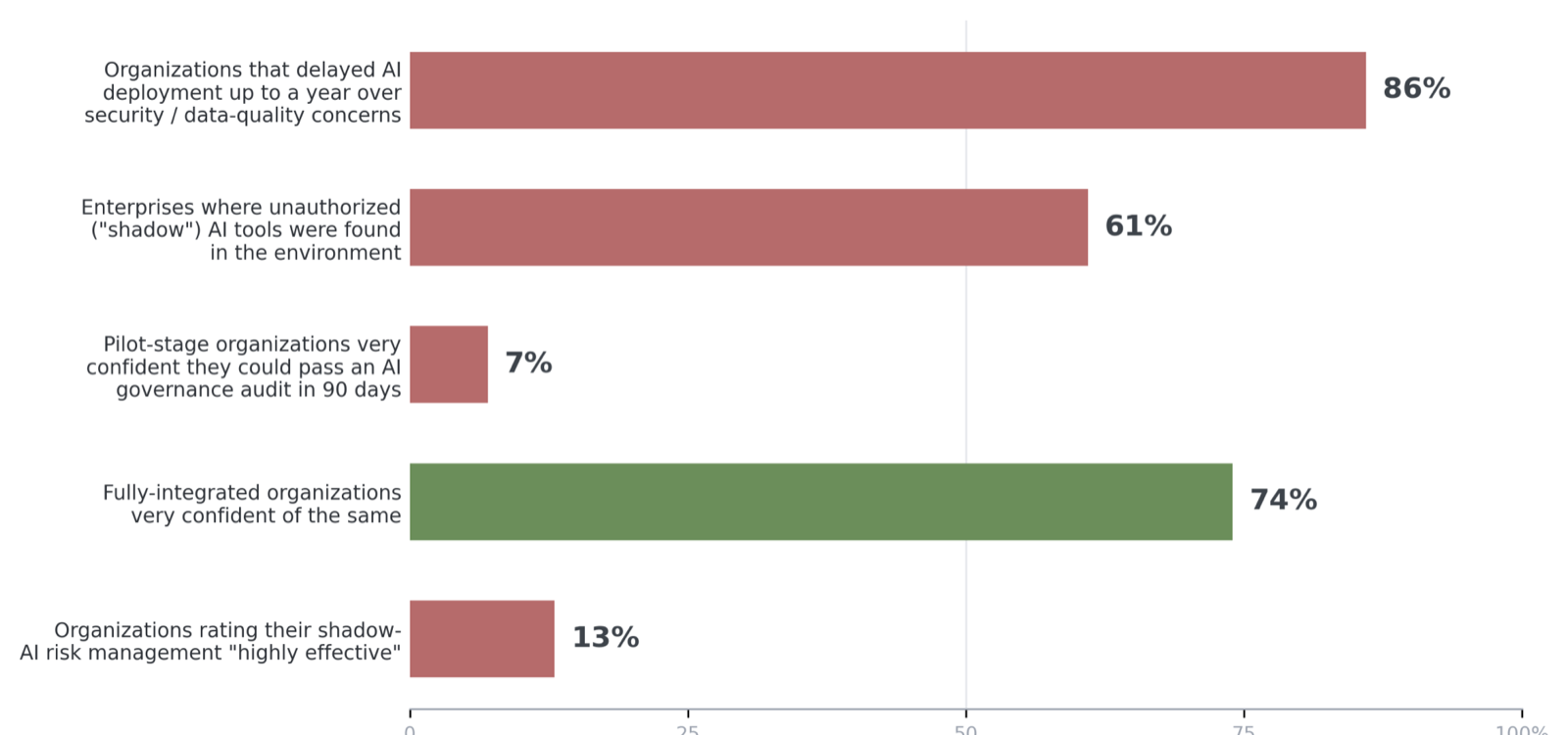
Figure 1. The cost of a restrictive default. Independent enterprise surveys, 2024–2026: delay and shadow use rise where governance lags, and confidence rises where AI is properly integrated.
The productivity gain is real and measured. A Harvard/BCG field experiment found roughly 25% faster work and about 40% higher quality inside the AI's frontier; a Stanford/MIT study of support agents found a 14% average gain, larger for novices; an MIT study in Science found a 40% time reduction on writing tasks. Every one of them depends on a human staying in the loop — the gain shows up when people keep a clear role in review and direction.
Security is a question to engineer, not a reason to stop
The legitimate concern is data handling, and it has concrete answers. lateralworks runs AI on a configuration where conversations are not used to train models, with short retention; stronger contractual and isolated postures are available when the data classification calls for them, up to a firewall-isolated deployment that keeps data on-premises. Match the control to the data, not to the fear.
A framework you can adopt now: three lanes
Replace a single yes/no with three lanes, keyed to data sensitivity and whether a human reviews the output before it acts.
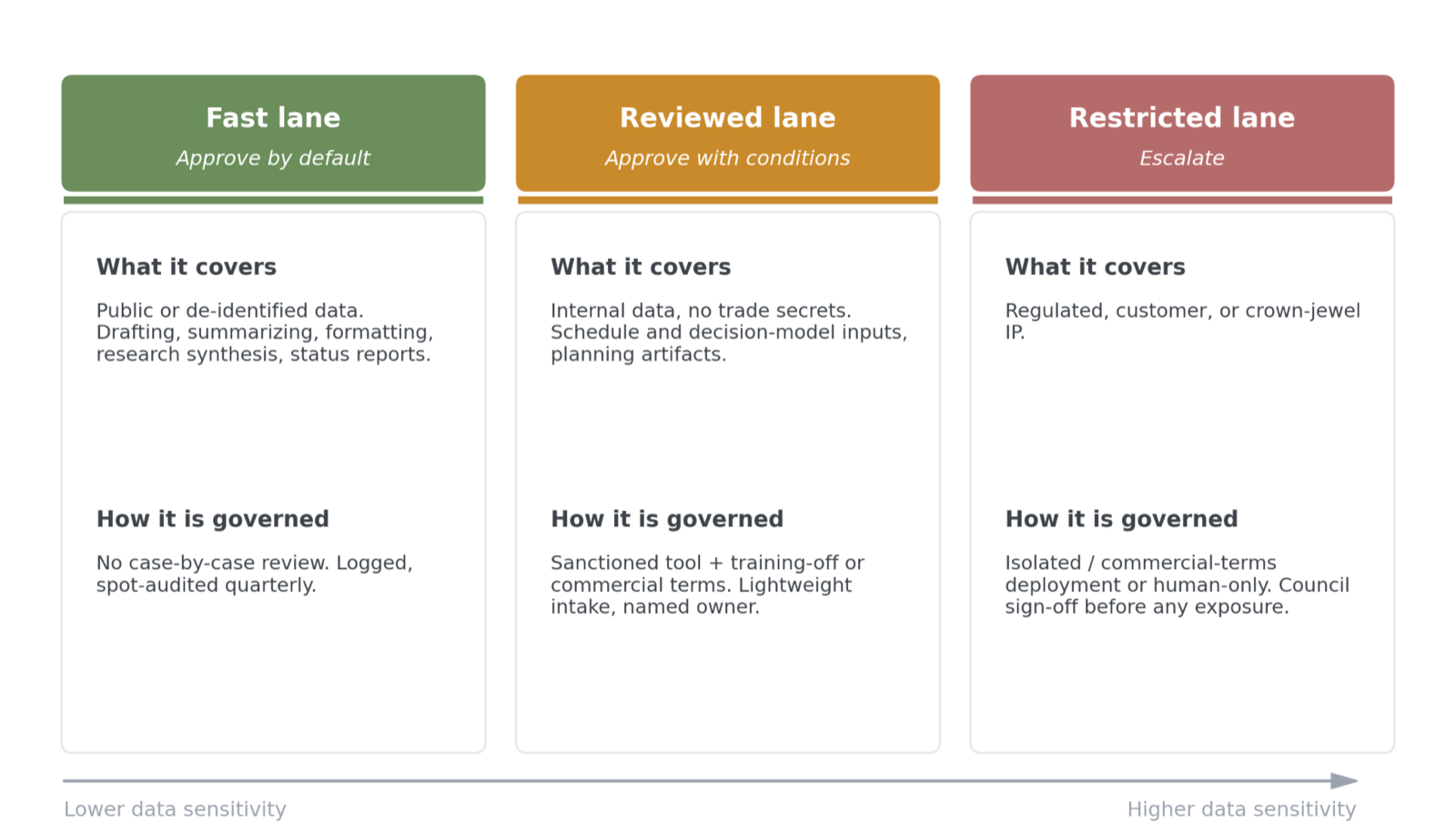
Figure 2. A three-lane decision rule keyed to data sensitivity. Each use is sorted into a fast, reviewed, or restricted lane, with a matching control. The rule is enforceable; a blanket ban is not.
Public or de-identified data with a human in the loop is fast-lane: approve by default, audit on a sample. Internal data with no trade secrets, through a sanctioned training-off tool, is the reviewed lane. Regulated, customer, or crown-jewel data is restricted: sign-off and an isolated or commercial-terms path before any exposure. A tiered rule keeps low-risk work moving and concentrates scrutiny where it belongs. It is also enforceable, which a blanket ban is not.
Score the work, then run the experiment
For priority, score each application on value — time-to-market impact, quality uplift, effort leverage — against risk-control — data safety, controllability, feasibility — so the choice is defensible rather than a gut call. Then, instead of writing policy from a guess, run a bounded experiment: an eight-week pilot on two live programs, governed by the three lanes, measured against criteria agreed up front, and ended by a hard go/no-go gate. At the gate, scale and codify, or stop and revise — on data, not on fear.
The one-line version: replace "stop until we have a policy" with "test under controls, measure for eight weeks, then write the policy from what we learn." It is the safer choice and the faster one.