Of course everyone knows it is impossible to plan when a breakthrough will happen. Planning requires some certainty about what is being done, how long each step might take, and some idea of when a solution will be achieved. But innovation is different. By definition innovation requires solutions to problems that don’t have known solutions, so how can one accurately predict when a solution will be found? How can the unknown be planned.
We have challenged the notion that innovation can’t be predicted over more than 25 years of development project work. We have worked on many bleeding edge/path finding technology projects where clients have pushed the boundaries of physics and known science. In the past, Research and Development were separate functions. Research was done in the lab and was not scheduled… it “just happened” when it did, while Development took place within organized NPD teams, that had budgets and target delivery dates. The later was managed, while the former just happened. This arrangement was tolerated when technology innovation cycles were slower, pre-1990’s.
Development projects could be mapped out with some degree of accuracy because the basic research to overcome the technological barriers had already been accomplished during the research phase, the team “just had to execute” on the development schedule to create a product and make it manufacturable. The problem for these incremental development projects was one of efficiency and organization, rather than simultaneously having to find breakthroughs.

We observed changes in this ordered and separated R&D world, starting in the 1990’s where Research and Development gradually merged, as product development cycle time was compressed and Research budgets were cut. Only the biggest of corporations could afford expensive research departments and Research Universities could not afford the Capex required to fund advanced research as tools and systems for development became more expensive.
Suddenly no one had five years to do the foundational research and then another three-five years to commercialize those concepts into a new product. We watched the average R&D cycle time in Silicon Valley go from 5-7 years in the 1980’s to 10-15 months in the 2000’s. In fact in the Storage Systems business the cycle times are less than 6 months and in some software environments much less. As cycle time went down, complexity exponentially went up. R&D merged so that teams had to innovate and develop almost simultaneously. What we saw were many innovation development projects that missed their target market windows - by a lot. Blame was placed on the engineering team (it always is) for not being able to innovate on a schedule/on time.
But they were essentially doing basic research during product development, so it was understandable that they could not hit the target schedule that was only set up to measure development time.
Engineers would push back and say “Innovation can’t be planned or predicted” because we don’t know when we will find a solution to problems we may not even know we have, until we experience those problems, and then we need to figure out how to solve them. How can we predict when we will solve something that we have never solved before? The result of this conundrum were huge cost-of-delay charges, products that totally missed market windows, and a lot of frustrated people pointing fingers.
Even worse, people were using historical development metrics to measure projects with high degrees of innovation components. We saw one storage systems project in which three major innovations were needed within what was their normal 18 month product development time frame. No account was made for the Research needed (of another 2 years that should have been tagged on to the front of the 18 months). One of the innovations involved an extremely complex software architecture redesign with a team of over 400 firmware engineers and a completely different method of writing data to media that had only been proven theoretically on paper, but never successfully implemented in a lab.
The innovation and productization was all expected to happen in less than 18 months and at one point a stretch goal was set for the team to do it in 12 months due to a competitive threat. In the end, they delivered it close to their target using some of the techniques we will share below. They implemented other best practices such as redefining the target market segment and narrowing down the product scope to a minimum viable product feature set, but these topics can be discussed in another post.
Most of the work we do with clients involves breakthrough technology. More than 50% of the projects we see require major technical breakthroughs to be achieved in order to develop and release a product. Perhaps because of our location (Silicon Valley) and partly because we have done a good deal of work in the semiconductor segment who tend to push the boundaries of physics and chemistry “on a 2-3 year schedule.” Innovate in this industry or die quickly.
But our experience has not been limited to chips and advanced node development. We have used the techniques discussed here on advanced software development, wireless technology, data storage devices, and in quantum computing and communications to name a few. In each case we challenged the idea that innovation can’t be planned.
This challenge involves five different ways of thinking about how to plan and manage innovation, including:
Learning Cycles
Learning Milestones
Iterative/Incremental Planning
Macro to Micro Planning
Isolate and Focus Innovation
Learning Cycles
How does one estimate the duration required to solve a problem, when there are so many unknowns? Unknowns such as why something is failing, what is causing it to fail, what might the possible solution be, how would it behave in each solution condition, how long will it take to run the DOEs (design of experiments), how many DOEs will be needed, what if none of the DOEs produce the expected results, and so on. The list is endless. So this is why people tend to give up and say that it is impossible to predict when a solution or innovation will be achieved.
Everyone wants to know “WHEN,” which is a most frustrating annoyance for any group of people struggling with the “HOW” and “WHY” part of the equation. “I’ll tell you when, when I know the HOW and the WHY…“ …”but when will that be?” “When I know HOW and WHY it is failing… you will know when, when I know…” It becomes an endless loop discussion.
Many years ago Tony Alvarez, who ran Cypress Semiconductor’s R&D group, introduced me to the concept of learning cycles as a way of approximating the duration required to discover solutions / innovate on a schedule. He learned the technique from T.J. Rodgers - the founder of Cypress, where I also heard T.J. explain the idea to disbelieving development teams. It is really simple and involves a series of sizing estimations.
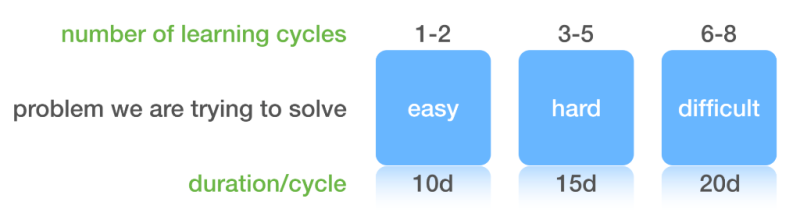
Any problem can be categorized in three groups; Easy, Hard and Difficult. A learning cycle is essentially “Plan, Do, Analyze” (or Plan, Do, Check, then Act). Going through this cycle one time results is more information about the problem being learned. Many problems require multiple learning cycles to find a solution. If a problem is “Easy” it may require 1-2 learning cycles of say 10 days per cycle, Hard could require 3-5 cycles at 15 days per cycle, and Difficult (bleeding edge) problems could take 6-8 cycles to find a solution which may take 20 days per cycle. Every industry has their own version of this with different cycles and durations, but you get the concept.
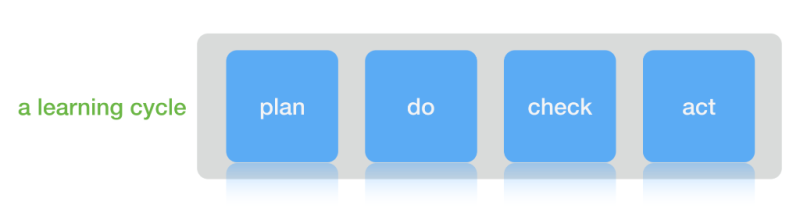
So if the problem you are trying to solve is “Hard” and you estimate 5 learning cycles to find the answer, then it is 5 cycles x 15d/cycle = 75 days duration. If you get lucky and find the solution in 2 cycles then you win and save time, if it takes more than 5 cycles you lose time, but it may only take 1-2 more to get it right.
At least you can predict the seven cycles and duration impact of the extended learning time required, and then make down stream adjustments. And at 75 days duration for 5 cycles you have an approximate estimate of the overall time that may be required on day one. This can be included in a schedule to approximate the end date of a project. It is better than making “wild ass guesses,” which we can safely say represents a majority of innovation project planning we have seen although this is masked by lots of data that make it look like people are really planning with certainty. The reality is usually that the target dates for the project become the schedule for the project, so no real planning is done.
The key is to define your learning cycle steps and the duration of each micro step to determine your typical leaning cycle duration for each of the three degrees of difficulty. The process of doing this usually stimulates ideas from the team about different DOEs they can run and what could be expected. One can also optimize each learning cycle to make them go faster or stagger them so the DOEs (or learning cycles) run in parallel. Use Learning Cycles to improve your estimating and the accuracy/predictability of your development schedule.
Learning Milestones

In a typical development projects we identify the 4-7 major milestones in the project from concept to market introduction. These are based on the maturity of the product from early concepts though design, prototypes, low volume and then high volume manufacturing. These incremental development steps tend to be relatively easy to define, much harder to get a cross-functional team to agree upon though.
We define the end state for each incremental step leading towards product maturity from birth to life. This end state is called the “Doneness Criteria.” It defines when a milestone is done. For example Prototype Demonstrated means; HW/SW integrated and validated, system tested and verified in lab, installed with beta customers for one month, and so on. These are the criteria that defines the milestone’s doneness, ”It is done when the following is completed.…” Again, on a development project these are straight forward.
However, on a Path-Finding or Bleeding-Edge innovation projects they are much harder because you are usually trying to validate or prove a concept first before being able to make it into a viable customer product. For innovation projects we use a different incremental milestone approach. We don’t define the doneness criteria around product functions-features performance, but rather we define the doneness by what is needed to learned at each milestone step.
These are called Learning Milestones (instead of product development milestones). So in order to find the answer to a problem, the team needs to learn first. Each milestone is a successive step in the leaning process. In one case our client had two components that failed when combined. In order for the system to work, these two components had to function together for a long usage life. The problem was that one component heated up to over 2000 degrees Fahrenheit for a nano second. The heating was essential for the system to perform at the specified level, but every time it heated up the other component burned up. The system had to heat up like this, but it was not supposed to burn up the other part of the system. In fact it burned so quickly that they could not even test for the cause because the evidence disappeared so quickly. This was all happening at an atomic level which made it even more difficult to solve since it was difficult to measure or observe.
So the team was given the problem of finding the solution. And like all projects they were also give a deadline target when they must innovate. The project had already slipped past the market window and the competitor was about to release a new and superior product using similar ground breaking technology they had been working on for ten years. The team was pressed, “When will you solve this problem?” and “When can we expect to see customer samples?”
The first reaction was to build a classic development schedule with incremental development milestones and then pull it in to get close to the expected targets. We tried this and it was not working. Why we asked? Because we were trying to measure the wrong thing. We can’t make a product when the fundamental science does not work. It was obvious, but like all things “not so obvious” when you are in the middle of it. Only in retrospect did we really see what was going on and how our approach had failed the team.
What we needed to be measuring was the team’s learning stages from nothing through to a solution. The milestones then became the learning steps and the doneness for each became what they hoped to learn at each step’s conclusion. So the idea was to fail as fast as possible so that the team could learn faster. Faster learning meant faster solutioning. What was causing it to burn up? What were the incremental learnings that we needed to answer this question? So the schedule was structured around these questions, rather than the more traditional product focused performance metrics.
We started looking at other client innovation projects and realized this approach could be used there as well. However, each time it must be adapted to the problem, but the concept is to build a schedule from incremental learning steps based on learning increments of “try it, do it, and fix it” failure cycles. The objective becomes forcing fast failure so that you learn faster which translates into finding solutions faster. More and faster cycles means faster solutioning.
The other trick is to run concurrent learning paths so you learn in parallel rather than linearly. The schedule then measures your rate of learning rather than the steps in a product life cycle document (used for traditional incremental development projects).
Iterative/Incremental Planning + Macro to Micro Planning
The problem with innovation is that you don’t know what you don’t know. When you move forward towards a solution you learn more, so why do people build detailed schedules of future work on innovation projects before much is known?
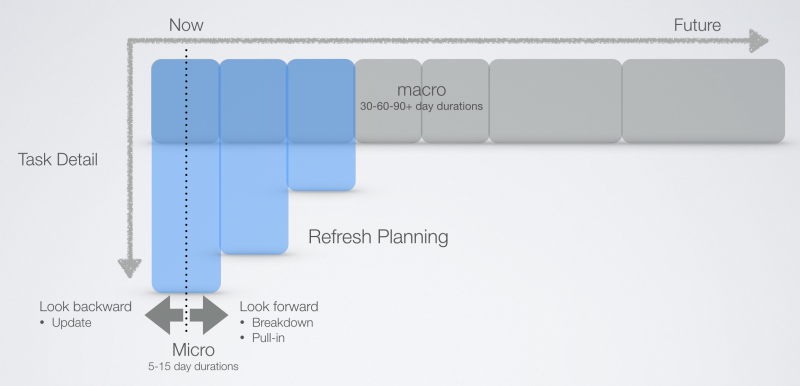
Rather, we use incremental or iterative work breakdown to construct more predictable innovation schedules. The near term looks more defined than the future tasks in the project, which are vague, chunky and less defined. We use the Refresh Planning process each week to refine the near term schedule and use this to inform tasks in the future. As time moves forward the schedule gets refined and decomposed into micro tasks (from the big chunky macro durations) when more is known.
We had one client that built out a schedule into 3500 tasks in the first week of the project only to find that after a few months the architecture for the chip totally changed making most of the back end of his schedule useless. When we started again to plan this project we planned all the way out to volume production at a macro level with about 50 tasks that explained the whole project. We then detailed the near term schedule and broke the product definition phase down into about 100 tasks with durations less than five days each.
We controlled the project with these 100 near term tasks and used the future macro tasks to approximate the release date and check it against the target market window. Every 4-6 weeks we could breakdown more of the near term so every few weeks 50-100 tasks were being added to the schedule. We only broke down the near term, leaving the future macro tasks as they were. We only broke down what we knew at the time. We adjusted the macro durations if we learned something through the near term work. This rolling window of brake-down continued to the end of the project.
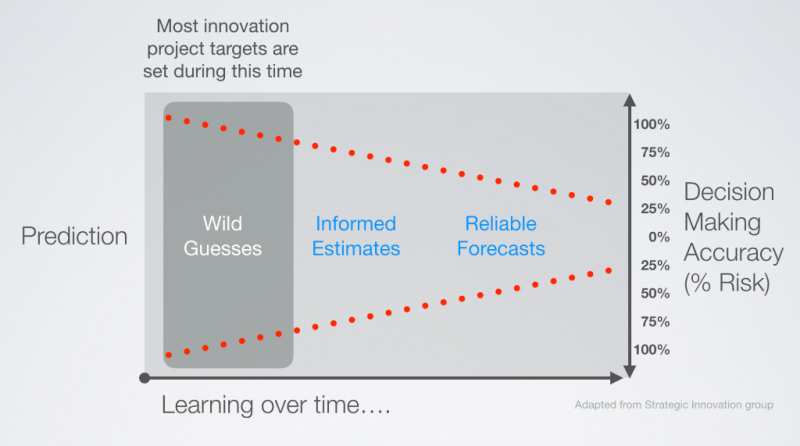
Why define what you don’t know? And worse, why define the unknown in tremendous detail? Yet this is what most project plans look like. Innovation planning requires this sort of incremental planning approach, because not enough is known at the start of a project to plan anything in much detail past a few months. The learning gained early is used to refine the future tasks in the project which remain macro until enough is known to be able to break them down into detail.
Just like product design; you use learning from early simulations and experiments to define a prototype and then the prototype into a final design. One does not define everything from concept to final design in nth-level detail, because things change as you learn from your early work. Define what you know and leave the rest vague and approximate.
Why isn’t this obvious and why doesn’t every innovation project use a form of incremental macro to micro planning? Because some people think that detail equals accuracy. A detailed plan to the end means that the schedule is more accurate. But this is a false conclusion. Our friend with the 3500 task plan thought he had a very accurate plan because he had lots of detail. But it all changed and was obsoleted when the product design changed.
Detail just means a lot of wasted time making up things before you have enough information to make rational estimates. Incremental planning is the only way we have found to plan cutting edge technology development, because you can only plan today what you know and approximate what might happen in the future. The near term is micro and the longer term horizon is macro, which gets refined when more is known today. So our planning process never ends and we never really have the complete schedule until the product we are developing has shipped.
Isolate and Focus Innovation
We can’t claim this idea as original, but love and use it all the time. The concept was developed by Preston Smith and Donald Reinertsen and described in their first book Developing Products in Half the Time https://www.amazon.com/Developing-Products-Half-Time-Rules/dp/0471292524.
They argue that most “innovation projects” are really mostly not innovation work, but rather a fraction of the project involves true innovation, while the rest is standard stuff that they have done before. They say that most pure innovation projects are only about 10% innovation and 90% made up of things that are known and have been done many times before. Or at least they should be architected that way to improve your chances of success.
The 10% innovation can hold up the other 90%. In some cases we have seen this happen. In my example above about the device that was burning up, we saw this phenomenon. About 250 people working on the project we transfixed with the Physics and Material Science problems manifesting itself in what seemed at the time to be an unsolvable problem.This indicated to them that they could also slow down and adjust their schedules to the slow pace of innovation they all expected. “Why rush now on my stuff, it will be years before they solve that problem…”
So while most of the team watched a few research scientists and engineers struggle with the burning-up problem they let some of the “easy” stuff slip by like mechanical design, IC Design, and integration which they were historically experts at in this company. The critical path became the “easy stuff” while the small research team working on the problem reached a solution sooner than anyone expected. The long pole got shorter, but they all expected the long pole to get longer. The short poles of things they knew how to do became the gating areas in the schedule and then the new long poles of the critical path.
The best practice teams identify the required innovation at the start of the project. They isolate it from the rest of the project and fully fund and staff it with dedicated resources. They start it early and give it more time. This runs concurrently with the other 90% of the work (the easy stuff) and is timed to intersect early enough during preliminary product integration so that it the solutions can be validated early if more learning cycles are needed.
The key to innovation is to start early and give it longer than is required. Decouple it from the critical path and run it in parallel. Assume it will get resolved in time and adjust if it doesn’t as you learn more. But the key is to identify the breakthroughs that are needed and dedicate a group of people to finding the solutions. Make sure they are not the same people that have to also do the easy bits on the project (the other 90%) or the hard stuff will get compromised and will not finish on time.
The other classic problem on innovation projects is that too many things must be invented in order to create the product. One, maybe two breakthroughs could be expected, but not 5-10. If there are too many innovations needed, then the schedule is unpredictable. Too many degrees of freedom will cause the project to spin out of control.
On another project they were trying to innovate the IC design, the manufacturing process, a new design concept, and a new firmware architecture. There were too many new things and the project ground to a stop. Nothing moved because everything needed breakthroughs.
To get the project moving, we were able to select another older proven IC design from a part that was already qualified, we went back to an older qualified manufacture process, we didn’t use the new firmware, and we focused on the real innovation which was a new way to accomplish something (TMI will give away what this was, so I’m being purposely vague).
We took a 2% yield hit, but this cost was totally overshadowed by the 10x gain in time to market (we shortened the project by 10 months @ over $4M of profit per day). The isolated new design idea turned out to be about 10% of the development effort. Once the scope was narrowed, the schedule started to accelerate. We eventually got the team back on schedule. The product shipped on time and was not compromised in any areas - it met all the customer requirements. Right product at the right time. Whatever costs we lost with the down scoping of the technology we gained back many times in the 10 month acceleration.
Conclusion
We use all these techniques (and more) to organize innovation projects. We are able to plan them, estimate their duration, and track their performance over time with some degree of accuracy. Innovation can’t be “scheduled” to occur exactly when you want it to, but it can be managed. It is better to be roughly right than exactly wrong. We teach this to our clients so they can do it independently. The skills and thinking can be taught and transferred.
Organize the project around innovation requirements such that innovation is minimized and focused with a dedicated team. Break the work down from Macro to near term Micro detail, refresh the schedule incrementally based on what is learned. Organize the work (i.e. the 10% innovation) around learning milestones that track what is needed to be learned and when it is needed to be learned. Accelerate these learning cycles so you fail faster and learn sooner. Estimate the duration of these learning cycles using T.J.’s simple “easy, hard, difficult” model.
Doing all of this will not ensure innovation projects finish faster or on time, but they will help you manage them and make schedules more predictable. Because being able to predict into the future is sometimes more valuable than getting their quickly, especially when you are at the bleeding edge. With the ability to see further, teams can make better informed decisions today that will influence the future. This will also stop the foolish guessing that we see on most innovation projects where people pretend they can do something faster than they really can.